
Since it has changed its name a thousand times, in this post I'll call it Clawd, which is how we first knew Molbot, now called OpenClaw, and tomorrow who knows...
This post isn't meant to be a guide on how to use Clawd, but rather a look at how we're rolling it out at Helmcode to have an AI Agent that helps us with our day-to-day work managing the Cloud infrastructure of multiple startups.
Setup
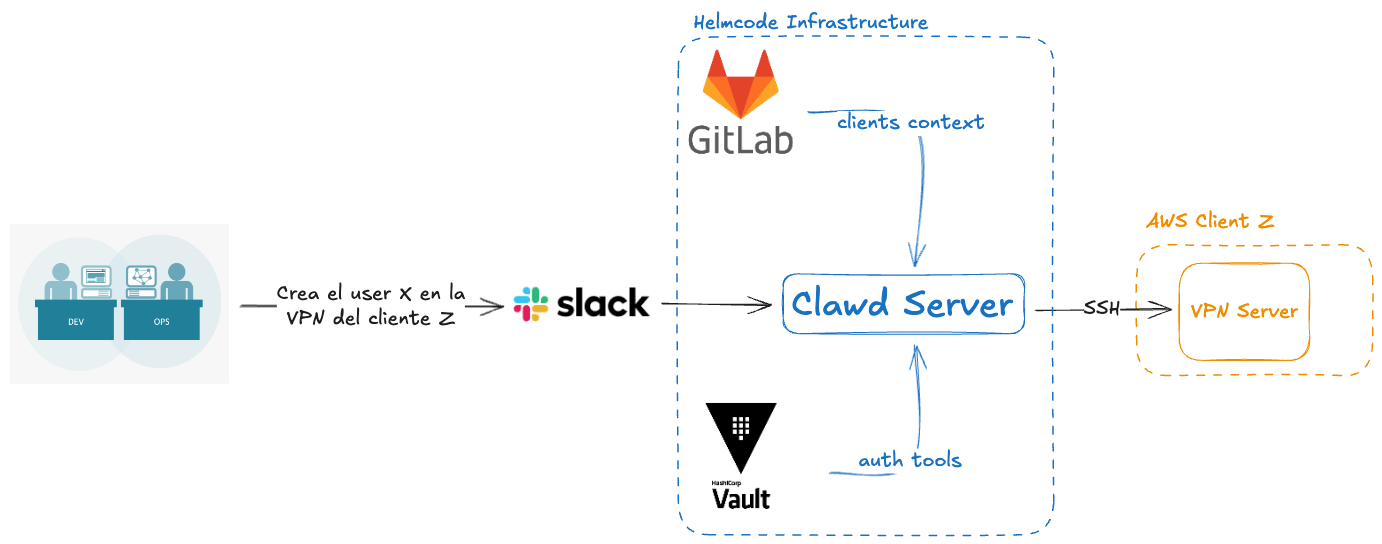
In our infrastructure we spun up an Ubuntu server and installed Clawd on it. We connected it to Slack, and it's only available in certain group channels.
The truth is its documentation is genuinely good, and by following the steps in its script you can have the agent ready to use in 30 minutes. The guides we followed at the time were:
- Installation with Anthropic's models.
- Slack configuration
Once the agent "came to life" inside the server, we installed several CLIs so it could interact with multiple tools (kubectl, argocd, vault, etc). We installed and configured them manually so that we control and pre-configure everything before Clawd interacts with them.
On GitLab, we created 3 repositories for different important parts of Clawd:
- memory: it's "the brain" of the agent. It generates and updates files in the format: YYYY-MM-DD.md to keep context of the conversations you have with it. On top of that, we moved the MEMORY.md file into this directory so it lives in the repository too. This file is the agent's "main" memory and takes higher priority than the other files it generates over time.
- scripts: the agent generates scripts for different things it needs or that we ask it for. For example, pre-loading a configuration so it can use certain tools. To keep all of this centralized, we've told the agent that it must store every script here so we keep this code in the repository.
- clients: this directory contains our custom "skills" with business logic, plus examples for the agent on how it should do certain things and how it can gain the ability to interact with the different infrastructures we manage. This part is critical, because it's also where we tell it how to interact with Vault to authenticate against each client's infrastructure.
The agent can update and push things directly to the repository in both memory and scripts. In clients, to update anything, it opens a PR for us to review before merging its changes, since we have to validate that those changes comply with our business logic.

Tests
The simplest stuff worked without a hitch. Asking it to check the system time or which user it runs as worked fine, but that was no surprise. Anyone who has worked or played around with agents knows that running commands in the terminal stopped being a mystery a long time ago (except with the AWS CLI, which is horrible and even agents get stuck on it from time to time 😂).
The interesting part was getting into slightly more complex flows. For example, here are some of the tests we've managed to run so far:
- Asking it to create a VPN user for a specific client. The flow to do this, broadly speaking, was as follows:
- Clawd reviews the context of the requested client to figure out how it should proceed and how it should authenticate with the tool it needs.
- It uses Vault to authenticate.
- It runs the action.
- It replies on Slack once it has finished.
- Asking it to delete several disks (Kubernetes PVCs) that were unused and had been left orphaned:
- Now, on top of that, thanks to the fact that we gave it instructions in its main memory on how to use our task manager's API, it not only did what was asked but also logged its own task.

- Finally, the most complex flow we've managed so far, the one that's starting to hint at the possibility of having an AI teammate working side by side with us, is the following:
- However, here we added:
- When it detects a new ticket, it analyzes what we're asking for and for which client, so it can figure out the context and the tools it needs accordingly.
- Then, once it has built an action plan for itself, it asks us for authorization through a Slack group before it can carry out its task:
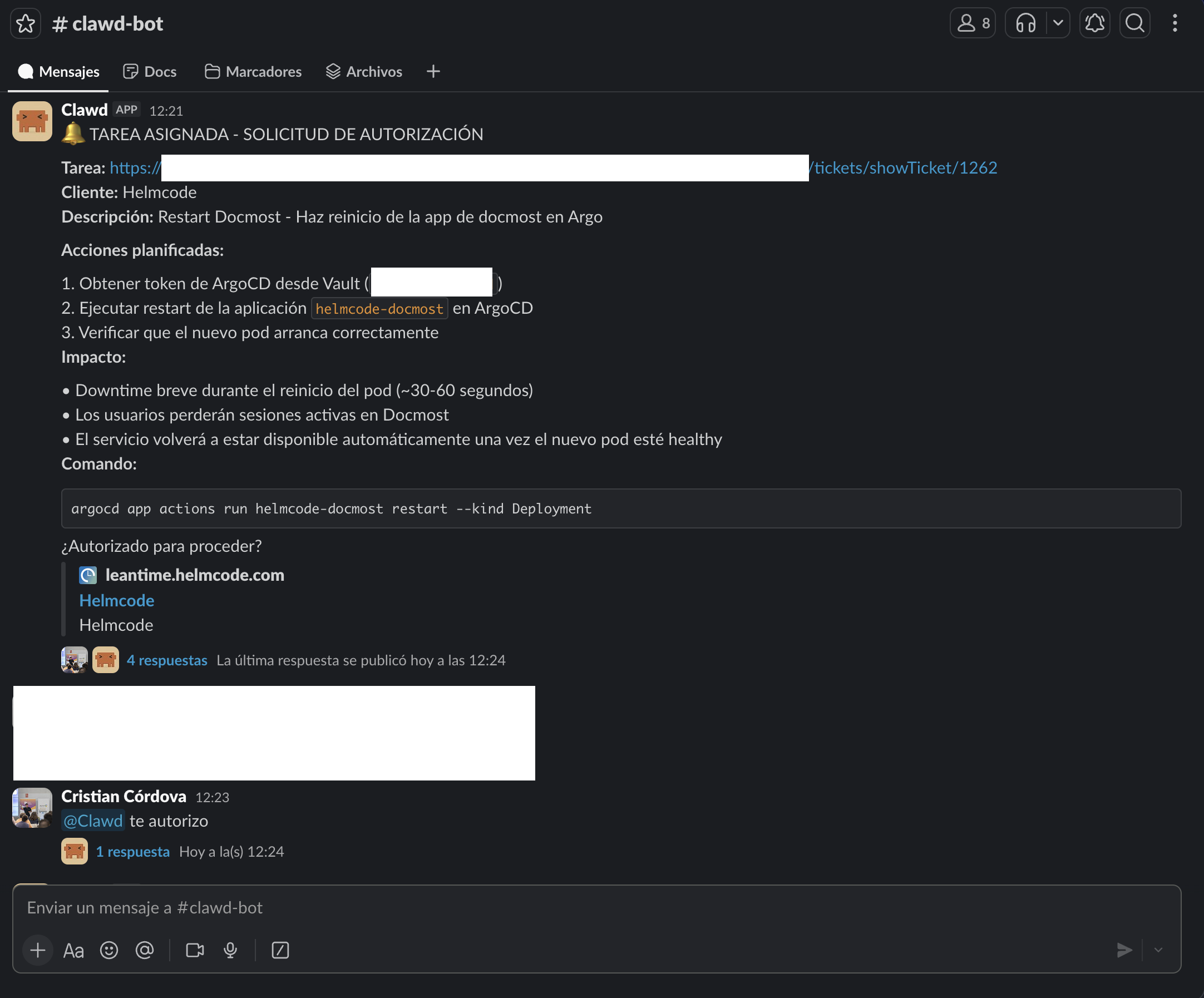
Finally, and ONLY after we give it authorization, it executes its action plan and reports back on the status of what it has done. When it believes its task is ready, it moves the ticket to the "Testing" status in our task manager and notifies us:
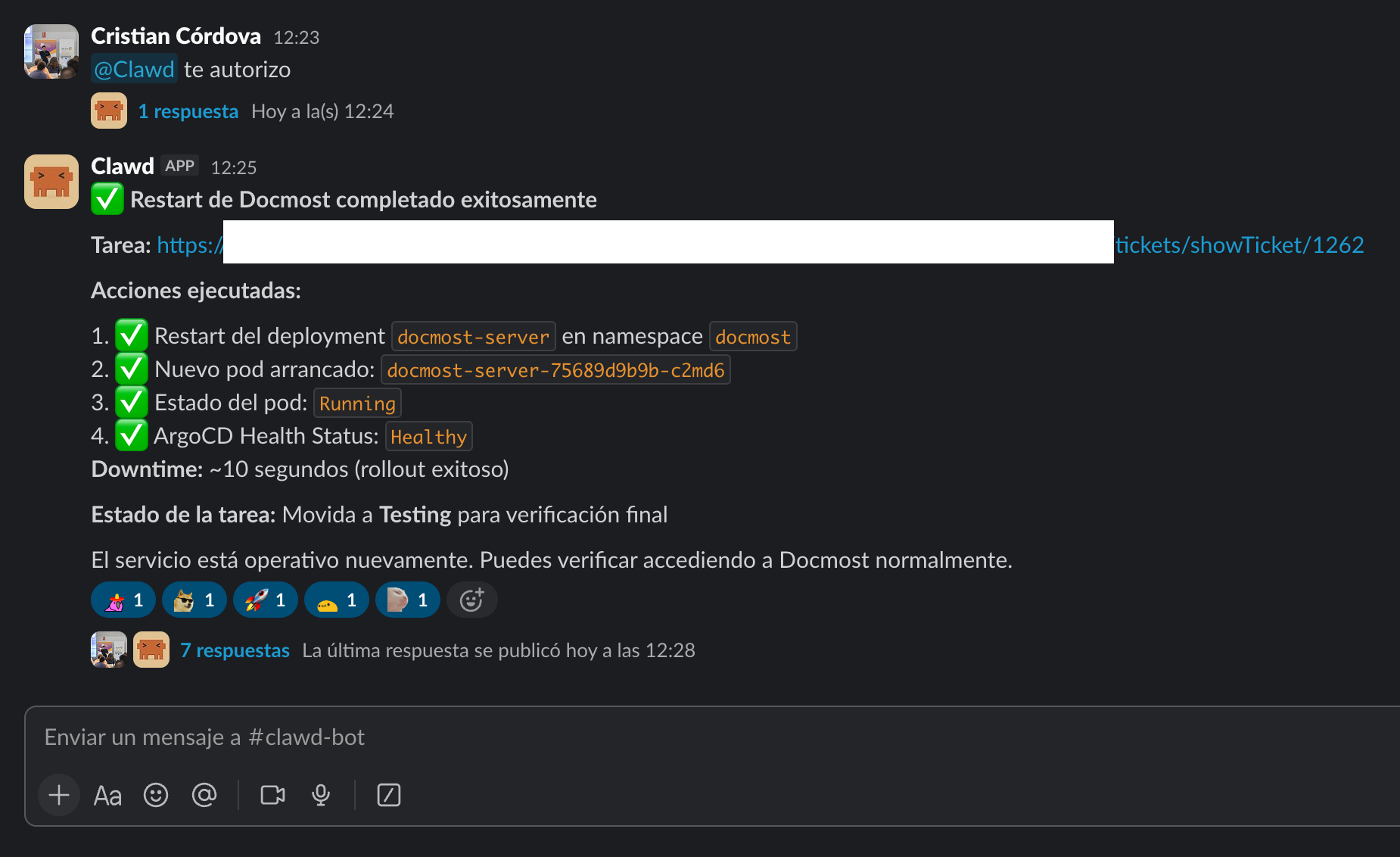
This way, someone from the infrastructure team (a human) can validate that what Clawd did is correct. If so, they close the ticket.
This flow no longer just requires processing on the agent's part; it pauses its processing while waiting for explicit authorization from the team, and it logs all of its work in our task manager, exactly as if one of us were doing their day-to-day tasks.
A few lessons learned
While the agent is a marvel and does incredible things, it requires a lot of context and proper documentation to know exactly what to do and how to do it. If you leave anything to chance, you're literally flipping a coin: you can get successful tests like the ones above, or you can get failed ones like this one that happened to us:

Clawd made its first screwup: an App wouldn't sync in ArgoCD, and the only idea it came up with was to delete the App. Fortunately, it did so without prune. In other words, as it pointed out itself, it didn't actually destroy anything beyond the Argo resource, which it then recreated, getting the task done, but the scare was real.
For safety, obviously, we're testing with applications and environments that are completely safe and that, if they break, get deleted, or something unexpected happens, are easily recoverable, which is why we can laugh about it. Still, it leaves us with a very clear lesson: running this without control, without context, and without clear instructions is frankly dangerous, and we need to be very careful.
Final thoughts
This is a very subjective opinion from the person writing this post ( Cristian Córdova ).
The industry is changing at a breakneck pace. The time when AI did more or less decent autocompletions in code feels like a century ago, and barely a year and a bit has gone by.
We're at a point where we can already say that 99% of the code written can be perfectly generated by some AI model. And not only that: now, thanks to Agents and MCP, they don't just generate things, they also have the ability to operate, as in the case of Clawd.
As we've seen, they're not 100% autonomous; they still require a huge amount of documentation, guidance, validations, and an endless supply of context to do what we actually want them to do. Fortunately, the models will keep improving and the technology will keep advancing, and this will get easier by the day.
I don't like making predictions about anything, so I don't know whether we'll lose our jobs, or be more necessary than ever, or who knows what happens, but what I am sure of is that I don't do my job the way I did it 5 years ago. In fact, not even the way I did it just a few months ago. So the important thing is to keep learning so we're ready for whatever may come.
I, for one, am extremely excited about all of this.
On Twitter , I'm sharing every day the different tests we're running, both the good ones and the bad ones. I'd be delighted to hear your feedback or ideas about all this. Until next time! 🖖


