
Before we start, a bit of context. The infrastructure is hosted on AWS and the architecture was based on Serverless services:
- API Gateway
- Lambdas (they ran a fairly simple Node service that received a set of parameters, serialized them, and inserted them into a database)
For the database we are using RDS with MySQL. Roughly speaking, the architecture looked like this:
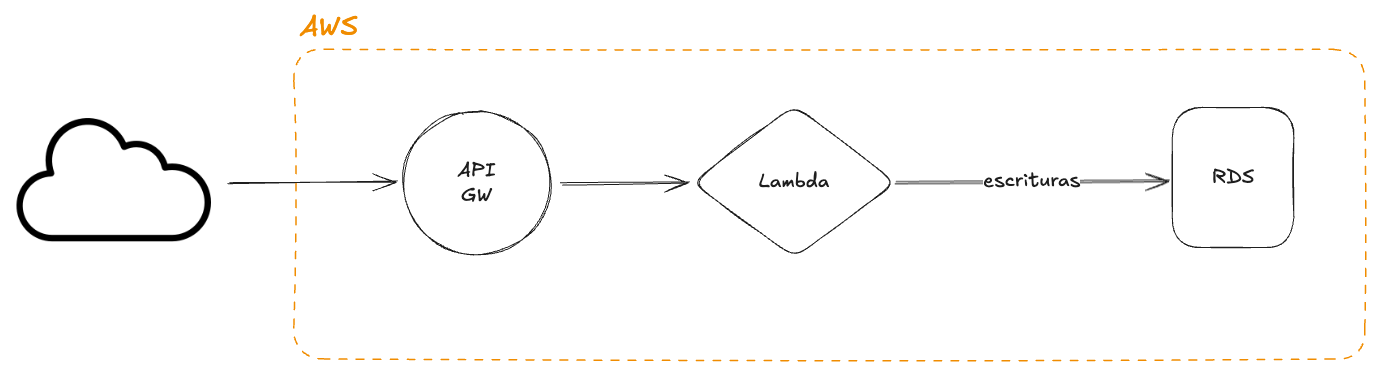
This architecture had three big problems:
- Due to the volume of constant requests we were receiving, the number of simultaneous Lambda invocations fell short. Even after raising the limit to 10K we hit the ceiling (the default is 1K).
- Because of how the Lambda was built in Node, a very high number of connections were opened on RDS, which forced us to scale up RDS resources since we were using a huge amount of RAM (we ended up with an instance
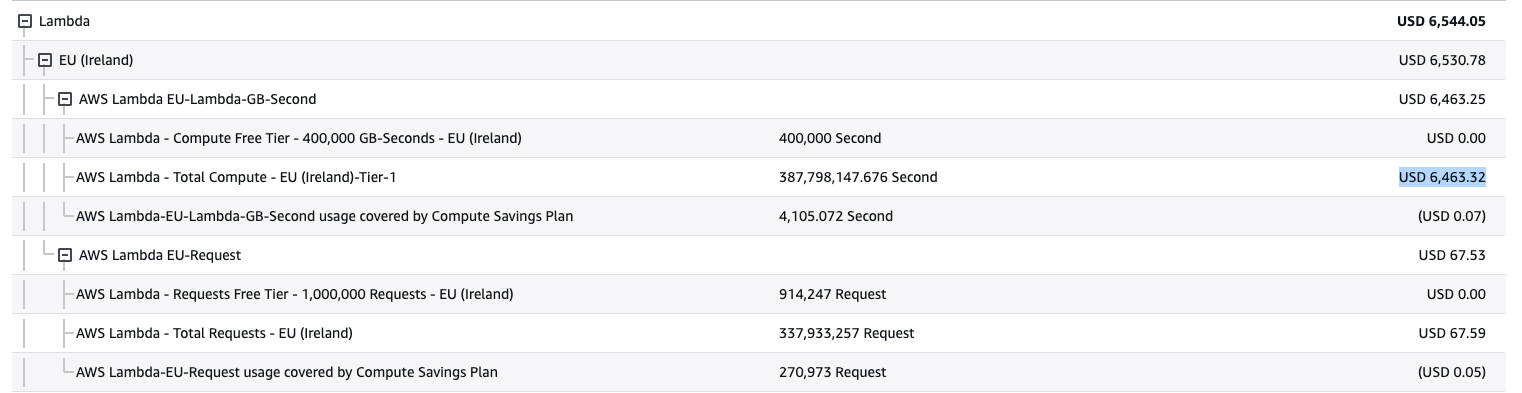
db.r6i.4xlarge). - The cost of keeping this running was enormous. In just one week we reached a Lambda cost of over $6.5K and AWS projected spend at over $36K. And all of this without even counting the fortune RDS was costing.
Changing the Architecture
Once we had identified the problems and bottlenecks of the current architecture, we needed to figure out how to drastically reduce the cost and also be able to properly handle all this traffic:
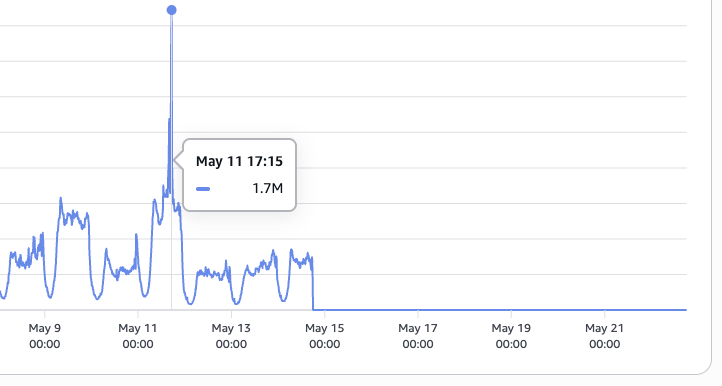
One of the latest spikes in calls to the API GW
At Helmcode we considered the possibility of adding some kind of queue system in between that would let us invoke Lambdas only at specific moments, but our volume not only fluctuates in spikes, it is constant, 24/7. And it just so happens that one of the problems with Serverless is that it is very expensive when serving recurring requests at such a high volume.
Since the Lambda function was also a fairly simple Node service and refactoring it down to an API wouldn't take us long, we decided to change the entire architecture. To do that:
- As the entry point we used ALB (Application Load Balancer)
- We took advantage of our Kubernetes clusters (EKS + Autoscaling Groups) that were already running other services.
- As for the Node service, we decided to split it into 2 services:
- A Worker that read from the streaming service and inserted events into the database in batches to avoid overwhelming it.
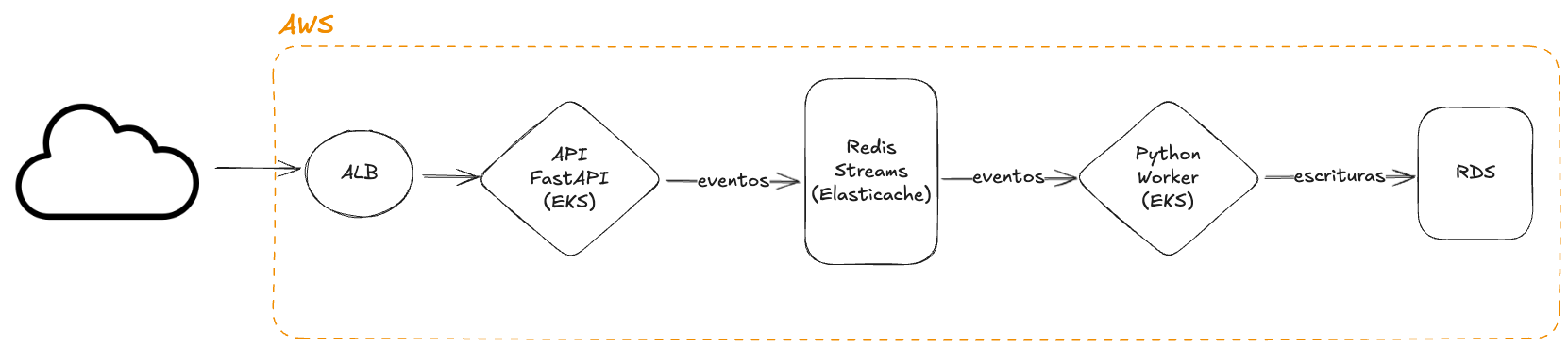
Architecture with Kubernetes
Some interesting things worth highlighting in the current Kubernetes configuration:
- We deployed 2 deployments, one for the API and another for the Worker. They have an HPA (Horizontal Pod Autoscaling) of:
- Worker: minimum 5 Pods and maximum 1o Pods.
With this new architecture we were now able to handle the traffic we had. On top of that, we solved two major problems:
- The limits on recurring Lambda invocations. With Kubernetes we have far more autoscaling capacity.
- Database writes, now done in batches instead of directly, caused the number of recurring connections to plummet, which in turn translated into much lower resource demand:
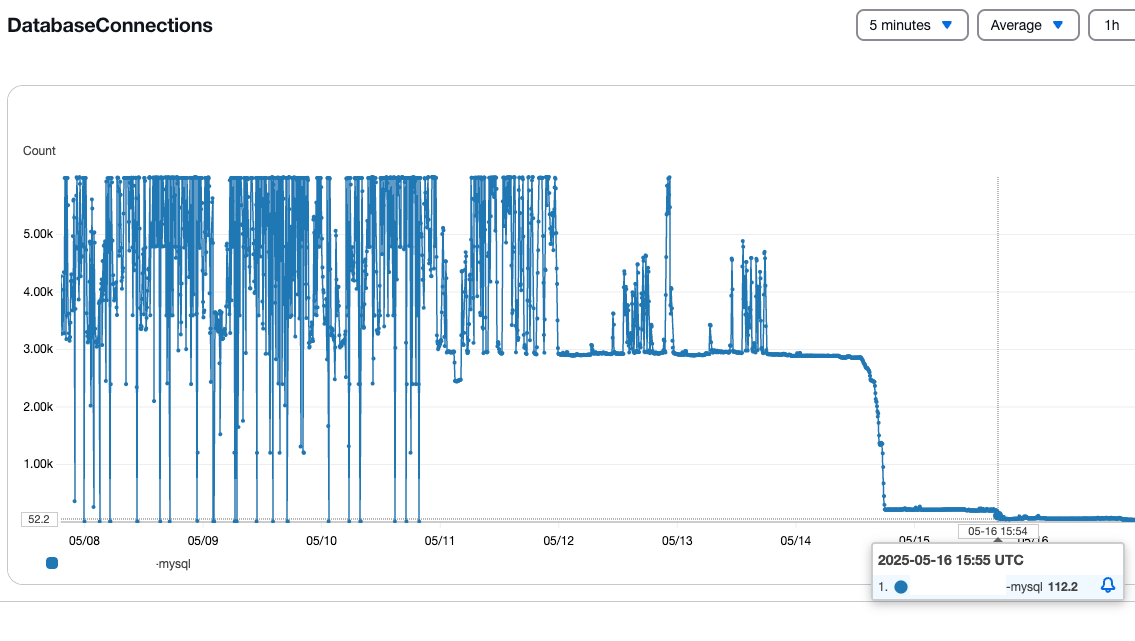
Simultaneous connections to RDS
Show me the money!
After a little over a week with everything running on the new architecture, we can now start drawing several conclusions and, above all, crunch the numbers on how much we are saving.
Serverless + RDS Infrastructure:
- API Gateway: over $1.2K with a projected spend of over $7.2K
- Lambdas: over $6.5K with a projected monthly spend of over $36K.
- RDS: with an instance type
db.r6i.4xlargethe projected monthly cost was over $1.5K
🔥 Total projected per month: over $45K
Infrastructure on K8s + Elasticache + RDS:
- Application Load Balancer: over $160, projected per month around $650
- Compute:
- EKS: over $103 with a projection of over $300
🤑 Total projected per month: around $2K

The projected savings from this architecture change come to around $43K per month. In fact, we can probably save even more because we are still evaluating whether we can lower the resources on some of the nodes, we need to verify whether we can adjust the instance types, and finally look into Savings Plans, reserved instances, and so on.
But that, most likely, is a topic for another post 👋


